Latent Diffusion Explained Simply (with Pokémon)
From Text to Image, Image to Image and Inpainting — the Latent Diffusion revolution.

Latent diffusion has been at the center of attention for the past few months, with people generating all sorts of images from text prompts.

Looking at the high quality makes you wonder what this technology could be used for in the future. And I’m not just talking about images. Imagine a 3D world procedurally built as a player explores a region in a game, designing novel enzymes for, say, digesting plastic purely based on a description, or even generating hypotheses/questions/corrections given a scientific paper (every Ph.D. student’s dream).
With this article, I want to dig deep into these models and (attempt to) explain how they work (with Pokémon). By the end, you should gain an intuitive understanding of what happens after typing your text prompt. I structured it a bit differently than I normally would: first, the topic is introduced, followed by some visual results and intuitions, and finally, a more in-depth explanation. Just as the famous quote goes:
“If you can’t explain it simply, you don’t understand it well enough”
Why Pokémon? Because you are probably familiar with the games and there’s a chance you have enjoyed playing them. Also, it is relatively niche, so it should push the model out of its “comfort zone” (i.e., less populated parts of the latent space ).
If you’d like to play around with the model, try out the demo here:
Alternatively, you can browse a collection of generated images using the search engine Lexica (https://lexica.art)
Let’s dive into some use cases!
Text to Image
Text to Image is probably the most famous application of latent diffusion models (at least according to my Twitter feed). Much like a conditional-VAE, we use a text prompt (y) to generate conditionally from the distribution p(z|y), thus serving as a guide to an area of the latent space.
I have experimented using “Pikachu” which I figured the model would have seen pictures of. Additionally, I have inserted the location prompts to be about The Starry Night by Vincent van Gogh and the Canary Islands. The former should push the model to draw a 2D Pikachu to fit the art style, while the latter, being a real-world location, could result in a 3D Pikachu.
Results

This is quite pretty — even considering the occasional deformities of the Pikachu. The first picture is probably my favorite as it even picked up the church-like building and added a field.

Definitely more successful in getting the surfboard and the water. An interesting detail is the dunes of sand in some of the images which you can find in the Canary Islands:

How it works
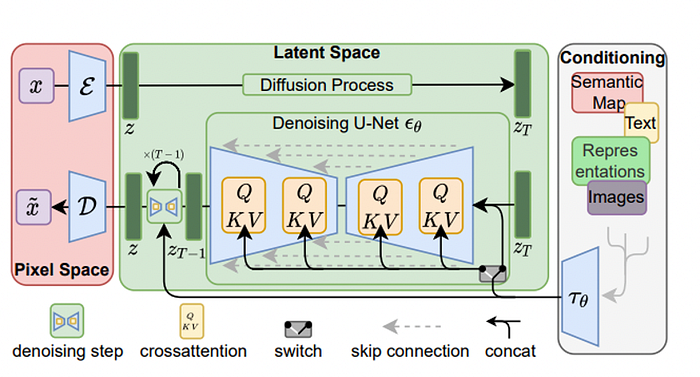
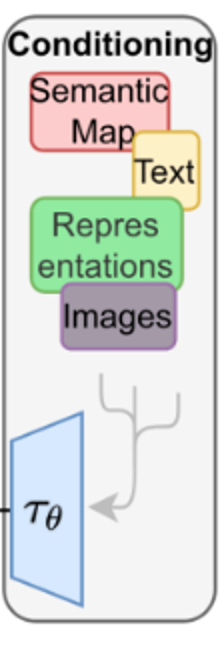
The input y is pre-processed by a domain-specific encoder (tau_theta) to produce a representation tau_theta(y).
The underlying UNet architecture is implemented with cross-attention layers, meaning that at each unit of the UNet, attention is calculated and then passed to later layers.
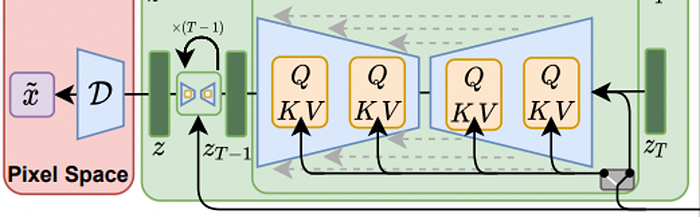
Attention is usually expressed with the Query, Key, Value terminology. Here, these values will be modified by taking into account the output of the domain-specific encoder tau_theta(y) as such:

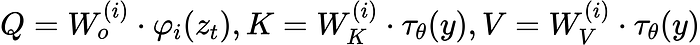
Meaning we are encoding our prompt to condition the de-noising step and therefore output an image that would fit the description.
Image to Image
This task is quite similar to the Text To Image. The input, however, is an image that serves as a prompt. The image is then encoded using the domain-specific encoder tau_theta(y) and fed into the model just like text. In addition to the image, you can also input a text prompt to guide the generation process further.
Results
My inputs to the models were:
- “A fire-type Pokémon spitting blue fire.”
- This doodle (I know, it looks terrible):

The results surprised me:

Most of these look Pokémon-like, and several of them integrate the blue as fire.
Unfortunately, none of them used the tophat as a tophat (we can blame my drawing skills for this), but most of them used the black color on the head.
Inpainting
Inpainting is the practice of removing or replacing objects in an image based on a mask. I remember back in 2010 (or potentially earlier) when Photoshop released it as a feature as part of their “Healing Brush,” and I was just astonished.
Latent diffusion models, you guessed it, can be used for this too! HuggingFace has a great intuitive User Interface where you can paint the mask on the image itself:
Results

The hat looks somewhat like a squashed version of the Harry Potter sorting hat — in the AI’s defense, we did give it quite a small mask. I also like that it adapted it to the style of the video game.
There are a few other elements to notice:
- There was an attempt at fixing the flooring around the hat. It’s not amazing, but it is a start.
- Dawn’s eyes appear darker and almost empty in the generated image. Her mouth also changed shape slightly. I believe this is due to the loss of information in the encoding and decoding step

Finally, I also tried to create a new character:

It has a backpack and a weirdly-shaped hat and legs. The “blue” prompt was taken up for the trousers and the hat partially.
How it works
Very similar to Image To Image, in the Inpainting process, we modify the masked area (“unknown region”) while keeping the rest of the image (“known region”) fixed. As with other models, we can input a text prompt which will be encoded and passed on together with the known region of the image. The model will then fill in the unknown region with an image that fits the shape of the region AND the text prompt.
Earlier, I mentioned how the latent representation offers advantages in computation and therefore speed. For Inpainting, latent diffusion models are at least 2.7x faster with a 1.6x increase in Fréchet Inception Distance (FID). This metric quantified the difference in distribution (mean and standard deviation) between real images and generated images rather than pixel-by-pixel metrics. The idea is that it tries to imitate the “perception” of similarity between images.
Other Uses
The paper presents other ways latent diffusion models could be used: image super-resolution and layout-to-image synthesis.
Image super-resolution is the process of generating a high-resolution image from a low-resolution one. It is particularly useful in biomedical applications like MRI scans. I doubt the model could be used effectively in such tasks without any re-training. However, with normal images, the results are visually pleasing:

Layout-to-image synthesis aims at generating images that fit a bounding box which guides the generation of an element in a specific position of the image. This is an example:

Limitations & Ethical Considerations
- One very intuitive limitation is that the model cannot generate images without any prior knowledge about a topic. For instance, without knowing what The Starry Night looks like, it would be impossible to generate images related to it. It would be interesting whether similar-looking images could be generated purely based on a text description and without any painting from van Gogh.
- Potential misuse of the AI model can have a significant societal impact, for example, creating fake images related to spam/news or offensive images. The original repository has several NSFW filters which hide the offensive images and also place an invisible watermark on the image, although it is not impossible to bypass it given the open-source nature of the model.
- These models are particularly susceptible to language bias and may display it in the generation of the images. Therefore, it is possible for the AI to misunderstand the prompt and generate potentially unrelated images.
- This model has been used to generate art and has even won art competitions (without the judges knowing it was AI-generated). Should this be allowed? Also, would you be interested in an art competition using (only) latent diffusion models?
☕️ Support My Work!
I’m Dr. Leucine, sharing insights on 🧠 knowledge management with Obsidian and 🍥 protein design. If you find my content helpful, consider buying me a coffee to keep the ideas flowing!
Conclusion
In this article, I covered three uses of latent diffusion models: Text To Image, Image to Image, and Inpainting. I explored (in the context of Pokémon) how each of these could be used to generate images and peculiar details for each generated image.
There are other ways these models can be used, for example for image super-resolution and layout-to-image synthesis. If you would like a more mathematical explanation of some of the parts of this blog post, I highly recommend the original paper:
or this blog post:
Disclaimer: all the generated images in this post have been created by stable diffusion (and me) using the official GitHub code:
If you do find any mistakes or inaccuracies, please feel free to comment/contact me, and I will update the article (and include you in the special thanks section).

